Published
Author Roderic Page

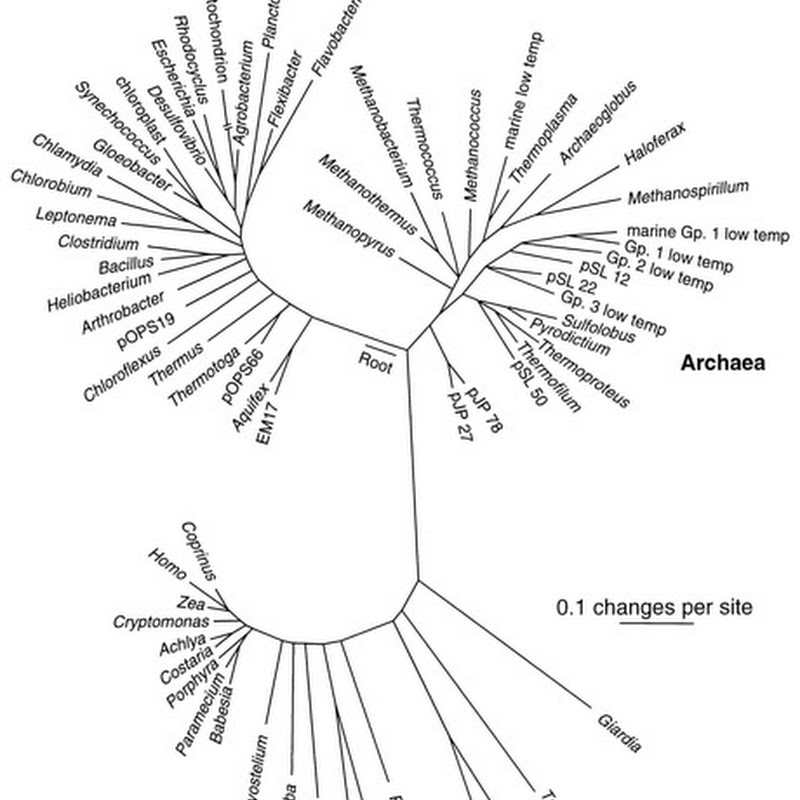
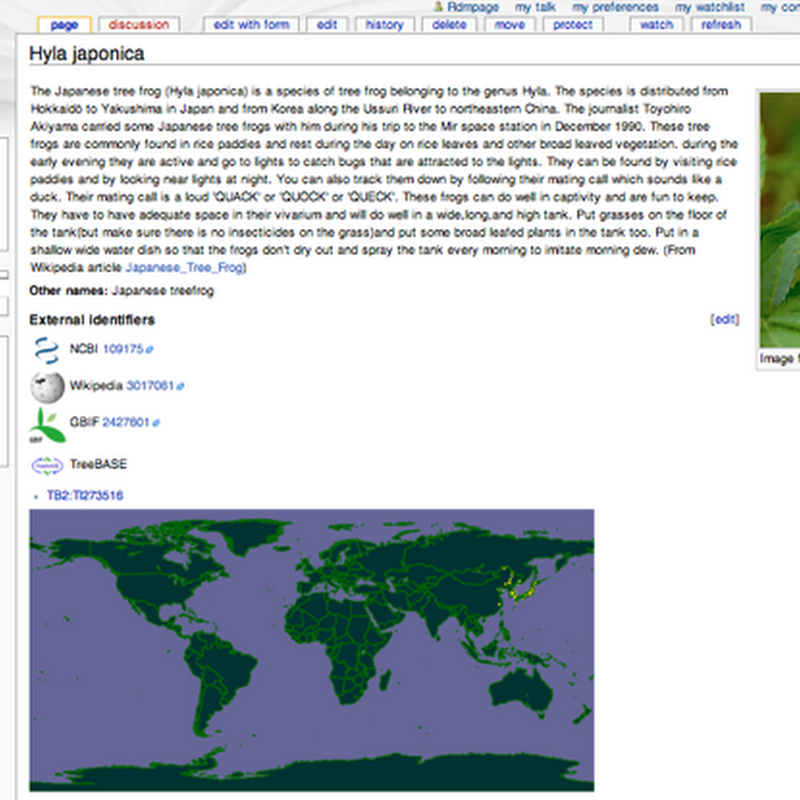
Half-baked idea time. Thinking about projects such as the Earth Microbiome Project and Genomic Observatories, the recent GBIC2012 meeting (I'm still digesting that meeting), and mulling over the book A Vast Machine I keep thinking about the possible parallels between climate science and biodiversity science.