Published
Author Roderic Page

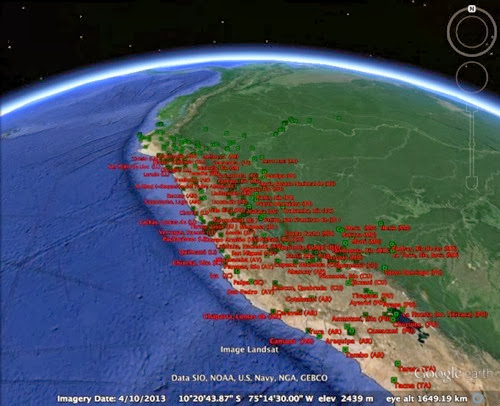
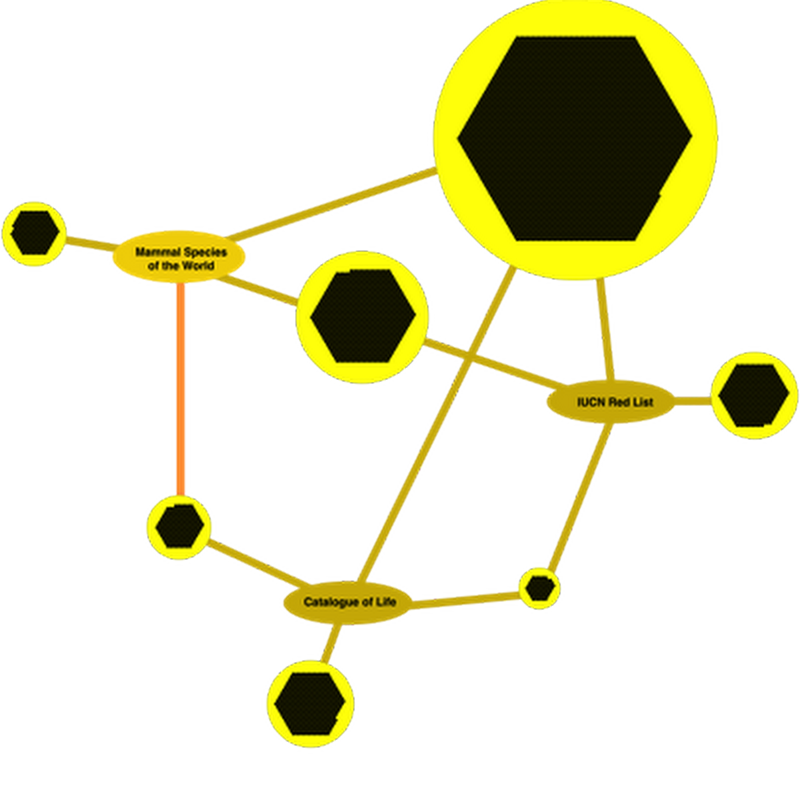
Quick notes on yet another attempt to marry the task of editing a taxonomic classification with versioning it in GitHub.The idea of dumping the whole GBIF classification into GitHub as a series of nested folders looks untenable.