Published
Author Roderic Page

Cooliris is a web browser plugin that can display a large number of images as a moving "infinite" wall. It's Friday, so for fun I added a media RSS feed to BioStor to make the BHL page scans available to Cooliris.
Cooliris is a web browser plugin that can display a large number of images as a moving "infinite" wall. It's Friday, so for fun I added a media RSS feed to BioStor to make the BHL page scans available to Cooliris.
Time for a Friday folly. I've made a clunky screencast showing an example of linking biodiversity data together, using bioGUID as the universal wrapper around various data sources.
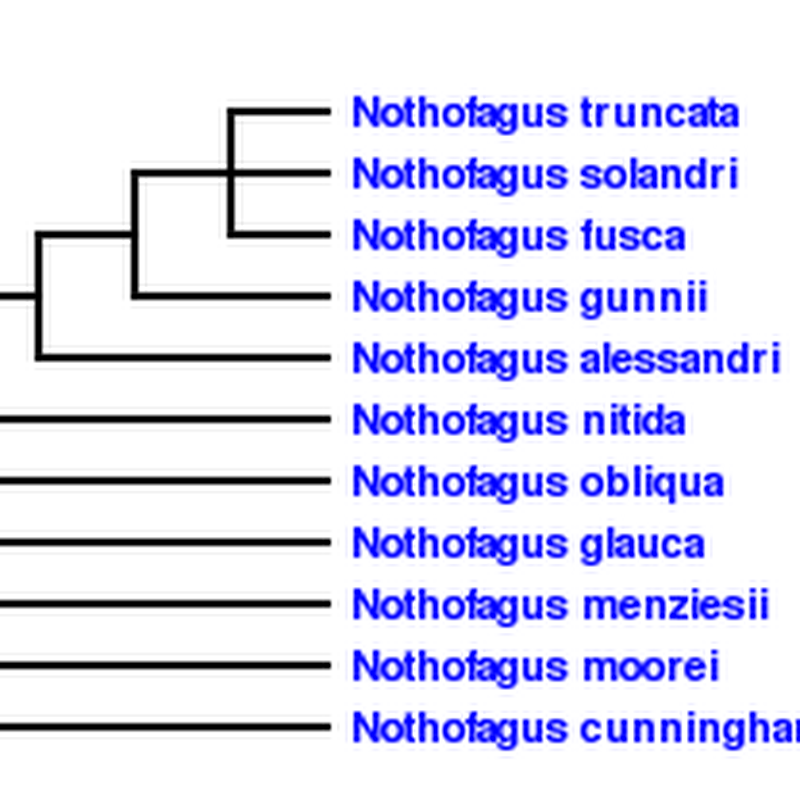
Some serious displacement activity. I'm toying with adding phylogenies to iSpecies, probably sourced from the PhyLoTA browser. This raises the issue of how to display trees on a web page. PhyLoTA itself uses bitmap images, such as this one:but I'd like to avoid bitmaps. I toyed with using SVG, but that has it's own series of issues (it basically has to be served as a separate file). So, I've spent a couple of hours playing with the element.
I've just spent a frustrating few minutes trying to find a reference in BioStor. The reference in question isand comes from the Reptile Database page for the gecko Phyllodactylus gilberti HELLER, 1903. This is primary database for reptile taxonomy, and supplies the Catalogue of Life, which repeats this reference verbatim.Thing is, this reference doesn't exist! Page 39 of Proc. Biol. Soc.

I'm in the midst of rebuilding iSpecies (my mash-up of Wikipedia, NCBI, GBIF, Yahoo, and Google search results) with the aim of outputting the results in RDF. The goal is to convert iSpecies from a pretty crude "on-the-fly" mash-up to a triple store where results are cached and can be queried in interesting ways. Why?
Thinking about next steps for my BioStor project, one thing I keep coming back to is the problem of how to dramatically scale up the task of finding taxonomic literature online.

To much fanfare (e.g., Nature News , "Linnaeus meets the Internet" doi:10.1038/news.2010.221), on May 5th PLoS ONE published Sandy Knapp's "Four New Vining Species of Solanum (Dulcamaroid Clade) from Montane Habitats in Tropical America" doi:10.1371/journal.pone.0010502.
Mendeley have called for proposals to use their forthcoming API. The API will publicly available soon, but in a clever move Mendeley will provide early access to developers with cool ideas.Image by Mendeley.com Given that the major limitation of the Biodiversity Heritage Library (from my perspective) is the lack of article-level metadata, and Mendeley has potentially lots of such data, I wonder whether this is something that could be explored.
The BBC web site has an article entitled Giant deep sea jellyfish filmed in Gulf of Mexico which has footage of Stygiomedusa gigantea , and mentions an associated fish, Thalassobathia pelagica .One thing that frustrates me beyond belief is how hard it is to get more information about these organisms. Put another way, the biodiversity informatics community is missing a huge opportunity here.
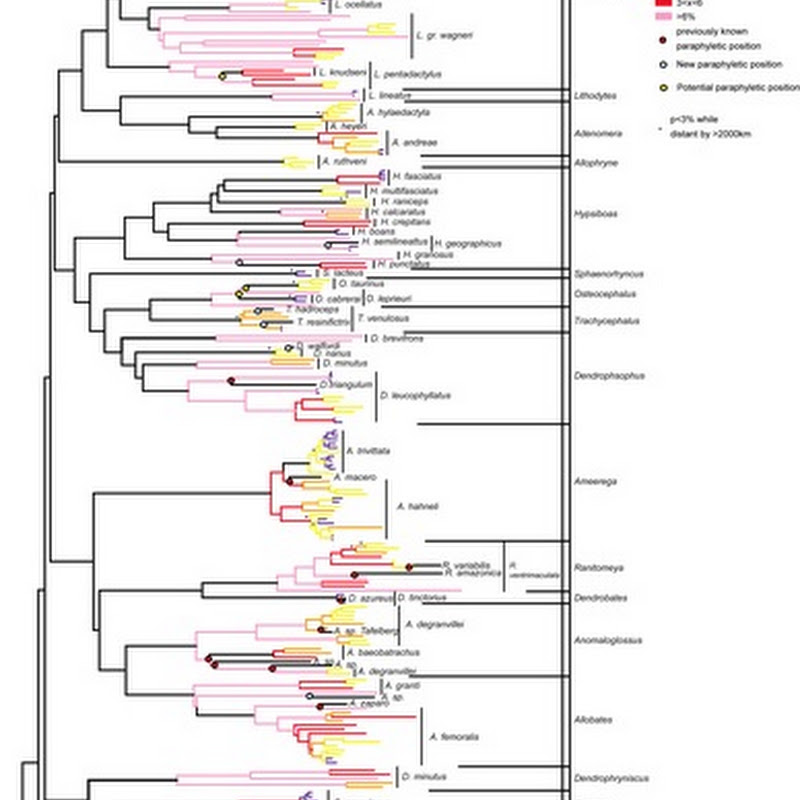
Random half-formed idea time. Thinking about marking up an article (e.g., from PLoS) with a phylogeny (such as the image below, see doi:10.1371/journal.pone.0001109.g001), I keep hitting the fact that existing web-based tree viewers are, in general, crap.Given that a PLoS article is an XML document, it would be great if the tree diagram was itself XML, in particular SVG.