Published
Author Roderic Page
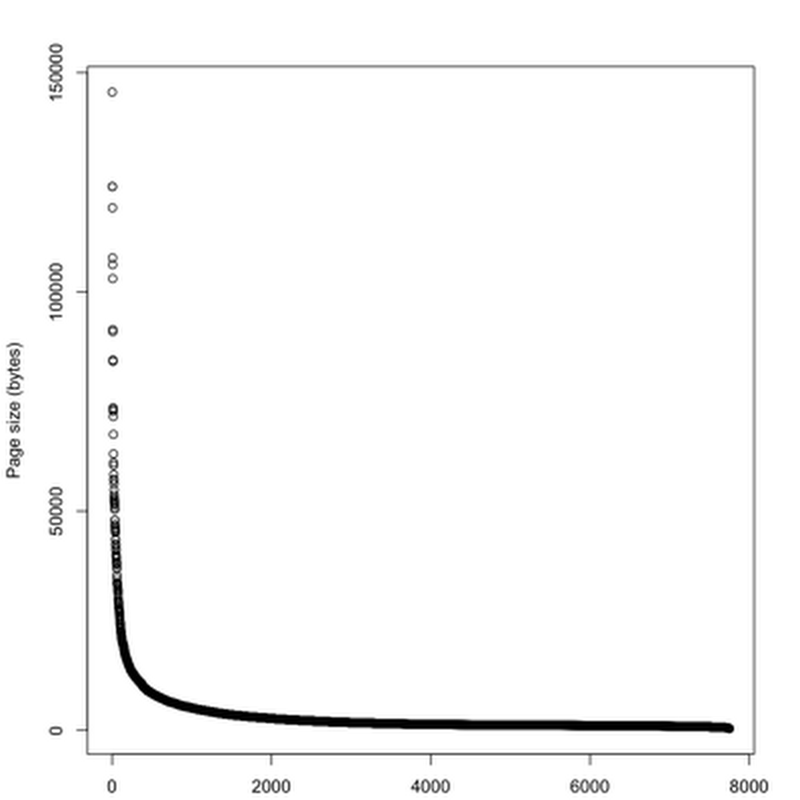
Playing a bit more with the Wikipedia mammal data, there are some interesting patterns to note.
Playing a bit more with the Wikipedia mammal data, there are some interesting patterns to note.
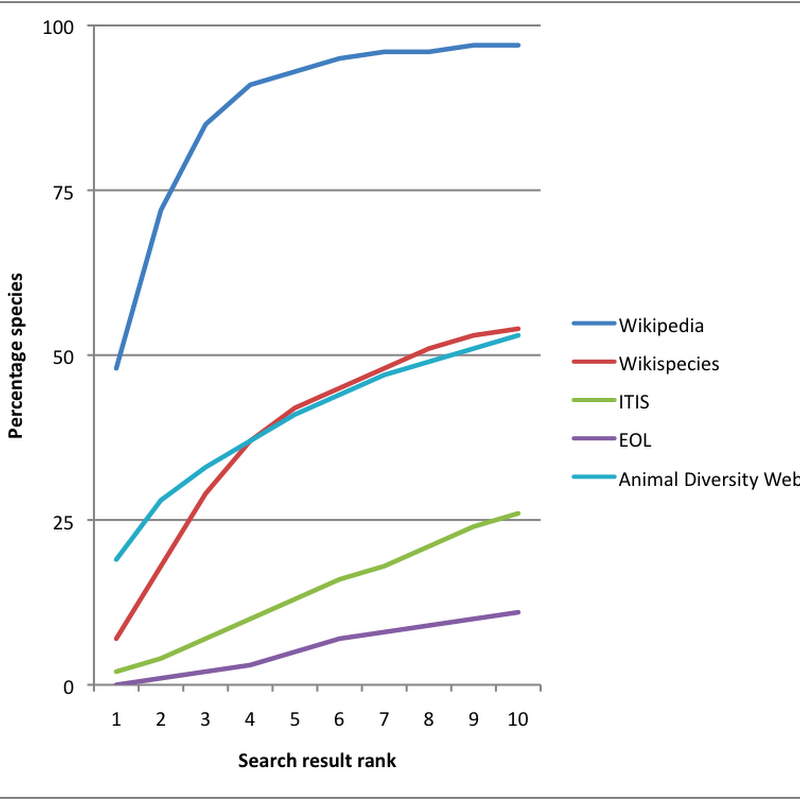
One assumption I've been making so far is that when people search for information on an organism using its scientific name, Wikipedia will dominate the search results (see my earlier post for an example of this assumption). I've decided to quantify this by doing a little experiment. I grabbed the Mammal Species of the World taxonomy and extracted the 5416 species names. I then used Google's AJAX search API to look up each name in Google.
One thing I find myself doing a lot is creating Excel spreadsheets and filling them will lists of taxonomic names and bibliographic references, for which I then try to extract identifiers (such as DOIs). This is a tedious business, but the hope is that by doing it once I can create a useful resource.
Short URLs have been a topic of discussion recently, perhaps sparked by the article URL Shorteners: Which Shortening Service Should You Use?. Many will have encountered short URLs in Twitter tweets. Leigh Dodds (@ldodds) askedI guess Leigh's talking about the need for short URLs in tweets, but I wonder about the more general question of why we need URL shorteners at all.

One advantage of flying to the US is the chance to do some reading. At Newark (EWR) I picked up Guy Kawasaki's "Reality Check", which is a fun read. You can get a flavour of the book from this presentation Guy gave in 2006. While at MIT for the Elsevier Challenge I was browsing in the MIT book shop and stumbled across "Google and the Myth of Universal Knowledge" by Frenchman Jean-Noël Jeanneney. It's, um, very French.

Google's Social Graph API was released earlier this year.The motivation:Apart from the obvious application to scientific databases (for example, utilising connections such as co-authorship), imagine the same idea applied to data.

Wired 16.01 has an article entitled The Data Wars by Josh McHugh. A quote from the printed version:It's a sobering read for those of us who advocate harvesting data from as many sources as possible, more so in light of Microsoft's bid to buy Yahoo. Yahoo provides free access to many of its tools via an API (such as the image search I use in iSpecies, and in this sense is much more open than Google. Might this change under Microsoft...?