Published
Author Roderic Page
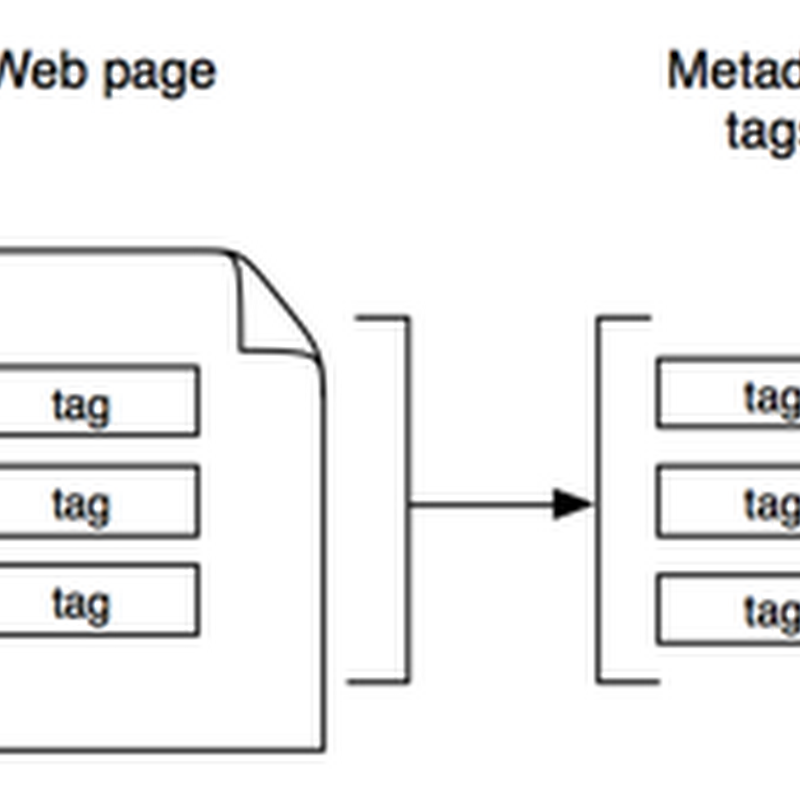
This is not a post I'd thought I'd write, because OpenURL is an awful spec. But last week I ended up in vigorous debate on Twitter after I posted what I thought was a casual remark:This ended up being a marathon thread about OpenURL, accessibility, bibliographic metadata, and more.




