Published
Author Roderic Page

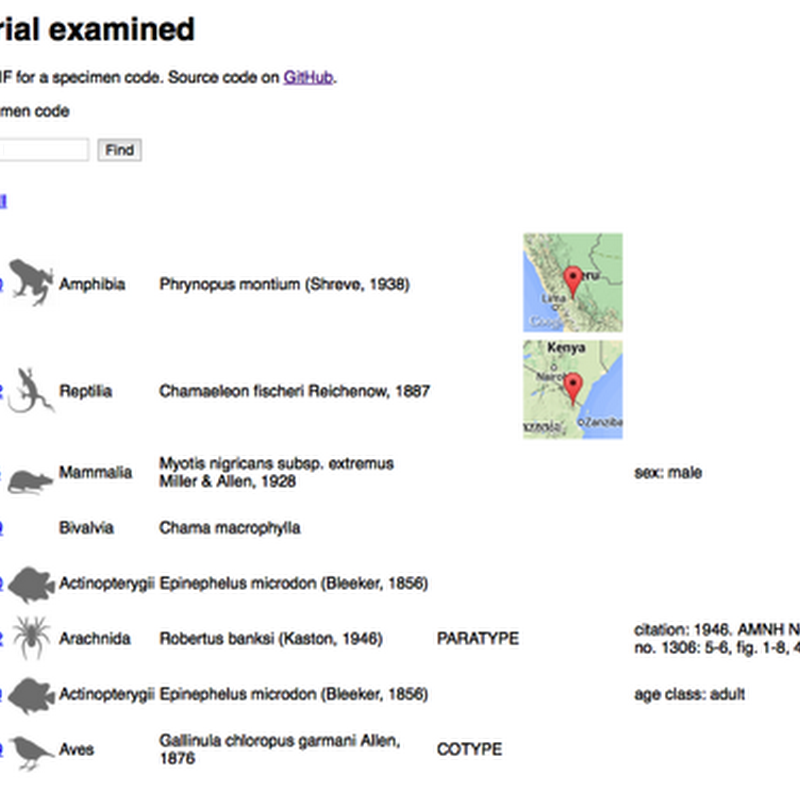
I spent last Friday and Saturday at ( Research in the 21st Century: Data, Analytics and Impact , hashtag #ReCon_15) in Edinburgh. Friday 19th was conference day, followed by a hackday at CodeBase. There's a Storify archive of the tweets so you can get a sense of the meeting. Sitting in the audience a few things struck me. No identifier wars, DOIs have won and are everywhere.