Published
Author Cameron Neylon
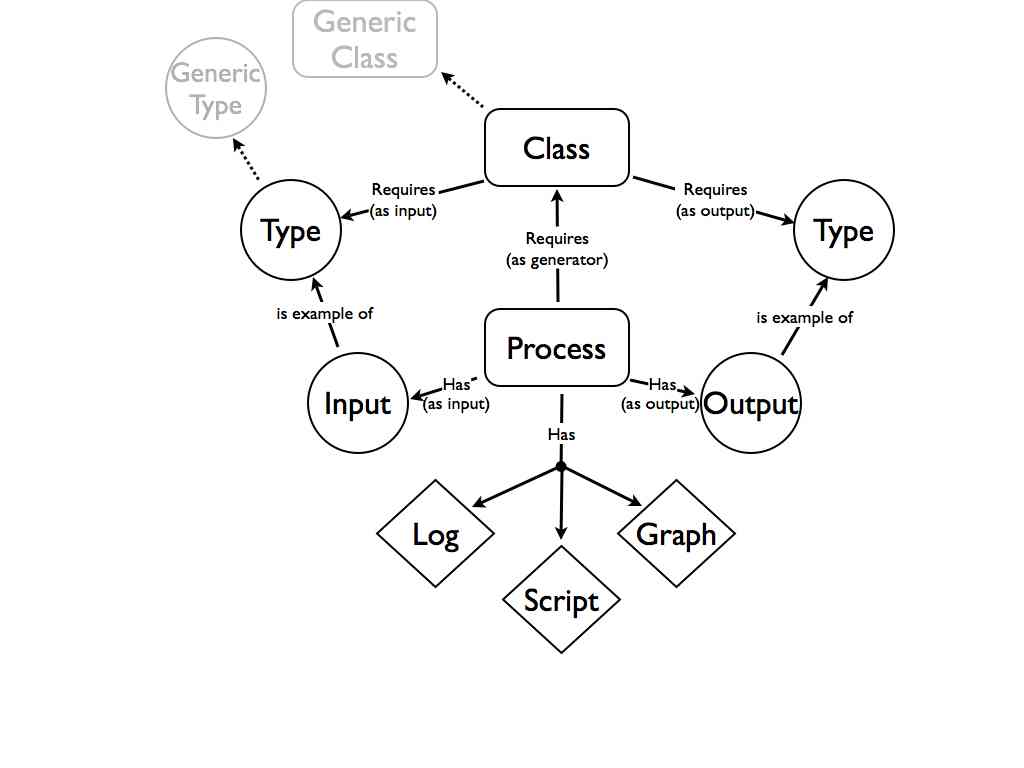
So in the last post I got all abstract about what the record of process might require and what it might look like. In this post I want to describe a concrete implementation that could be built with existing tools. What I want to think about is the architecture that is required to capture all of this information and what it might look like. The example I am going to use is very simple.